AI is being used more and more in healthcare for tasks like medical imaging, risk prediction, care management, and triage. That is great, but here’s an uncomfortable truth:
A model can be “accurate” and still be unsafe.
This blog post is the start of a monthly series where I’ll break down fairness in medical AI in a practical way, explaining how biases show up, how we measure them, and what actually helps.
Why bias can get worse with AI
Most people worry about AI getting predictions wrong, which is a fair concern. But there is even a bigger issue: AI can predict wrongly more for some groups than others.
A system can perform well overall and still be less reliable for specific groups. If that system is deployed at scale, those unequal error patterns also scale.
Healthcare data isn’t neutral either. It reflects who had access to care, who got tested early, whose symptoms were taken more seriously, and which communities faced delayed diagnosis. So the resulting biased model isn’t a result of malicious intent of the “powers that be” as some may think, it is the model learning those patterns.
The 3 layers of bias in medical AI
When a model underperforms for a subgroup, it’s tempting to just say “the model is biased.” But where is it coming from?
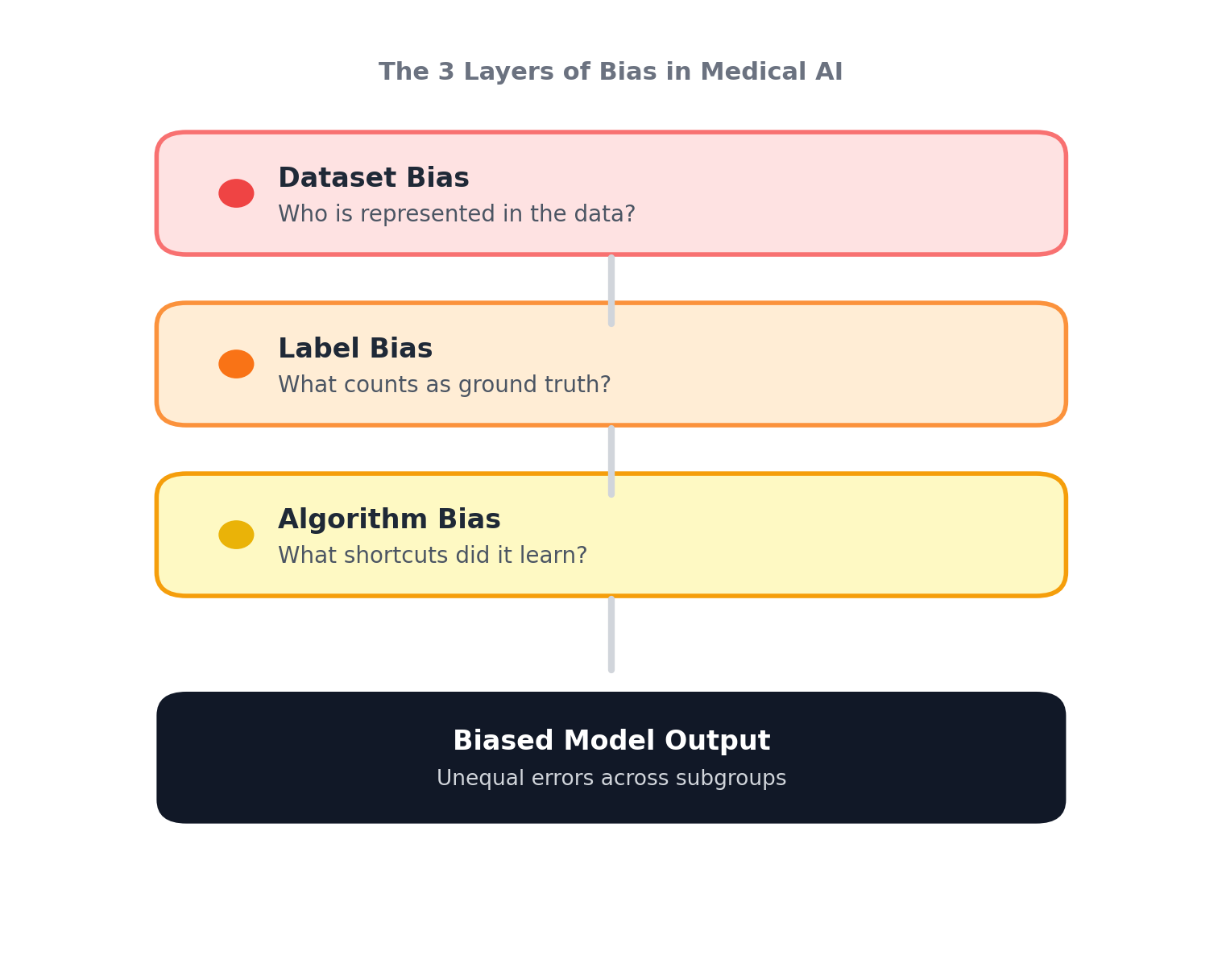
1) Dataset bias: If certain groups are underrepresented in training data, the model simply has fewer chances to learn them. Ultimately, that means less data on certain skin tones, age ranges, lower-resourced hospitals, or rare conditions. Hence, when models are trained on data of a certain predominant demographic, it falls apart when tested elsewhere.
2) Label bias: In healthcare, labels aren’t pure truth. They may inherit noise from clinician judgement, access to tests, and referral patterns. If the model learns those labels perfectly, it might just be learning from a ground truth polluted with noise inadvertently. Hence, as a result, the model predicts based on what it learned from the ground truth label, and sometimes misses the patient’s actual diagnosis.
3) Algorithm bias: Models can pick up on features that correlate with outcomes in training data but don’t generalize; this is referred to as heuristic shortcuts. They pick on features such as image background artifacts, site-specific imaging patterns, and population-specific signals. And as a result, produces models that are accurate on paper, but break under distribution shift or on subgroup performance analysis.
Why “overall accuracy” can hide harm

As shown in the figure above, imagine a dataset with 9,000 male patients and 1,000 female patients. If the model predicts all male cases correctly but misclassifies every female case, it still achieves 90% accuracy overall.
This is obviously an extreme example, but it illustrates how performance gaps stay invisible in imbalanced datasets, which is common in medical AI.
That’s why responsible evaluation means subgroup reporting, external validation across new hospitals and populations, and fairness metrics that match the clinical context.
“Fairness” isn’t one-size-fits-all
Fairness isn’t universal, and is different in various clinical settings, for example:
- In cancer screenings, false negatives can be more harmful (missed detection).
- In other settings, false positives can create serious burdens (unnecessary biopsies, anxiety, cost).
- In triage systems, fairness can affect who gets attention sooner.
So fairness is not just equal outcomes, but a way to compare reliability and safety across the groups the system will serve, in accordance with their specific priorities (must be justified).
A practical checklist that I have learned along the way
Before training
- Define the subgroups that matter for safety (not just what’s easy to measure)
- Check for representation gaps and missingness
- Identify label quality risks
During development
- Report subgroup metrics (not only overall AUC/accuracy)
- Validate across different sites and populations
- Watch for shortcut learning. Interpretability tools (e.g., GradCAM) can be employed for this.
After deployment (if deployed)
- Monitor performance drift over time
- Monitor subgroup drift as population changes
- Have a plan for retraining and accountability when failures happen
What is coming next
This series will go deeper into specific medical imaging domains, such as skin lesions, X-rays, and more, with a focus on how biases show up, how to measure them, and what interventions can best mitigate them.
Quick note: “subgroups” doesn’t only mean race, it includes age, sex, skin tone, socioeconomic factors, clinical setting, and more.
Disclaimer: This post is educational and reflects research and engineering perspectives. It is not medical advice.